# hooks 的出现解决了什么问题?
个人认为 React hooks 的出现主要解决了两个问题。
- 逻辑割裂
在 hooks 出现之前,React 主要通过编写 class 类来编写组件,每个组件有自己的生命周期,这就导致我们在编码时必须按照组件的生命周期去写,例如:我们在componentDidMount注册一个定时去,在componentWillUnmount销毁定时器。在componentDidMount中请求数据,在componentDidUpdate中判断状态变化请求数据。同样的逻辑, 我们需要在不同的生命周期中去实现,在一个大型的 app 中,类似的逻辑会有很多,掺杂在一起,越来越难以维护。 - 逻辑复用
在 hooks 出现之前,复用逻辑的方式主要是高阶函数和Render Props,但这两种模式都有它们自己的问题,那就是会出现「嵌套地域」。
对于高阶组件,我门的实现方式往往实现一个函数,它接受一个类并返回一个新类。这种方法确实可以很巧妙的解决一些逻辑复用的问题,但有一个弊端,如果一个组件被包裹很多层就会出现下面的情况:
export default withA(
withB (
withC (
withD (
Component
)
)
)
)
Render Props 也一样,这两种模式都会限制你的组件结构,随着功能的增加,包裹的层数越来越多,陷入所谓的 wrapper hell 之中。
Hooks 的出现是一种全新的写法,抛弃了类,使用函数来写组件。但由于函数没法保存状态,React 引入了 useState 等 API 来帮助我们保留状态。其中的原理是 React 会根据 useState 的调用顺序来在内部保留状态,所以 Hooks 有一个重要的规则,只能在最顶层使用 Hooks。使用 Hooks 编写的代码没有「嵌套地狱」,组织代码粒度更细,相关逻辑代码紧密,提升了组件的内聚性,减少了维护成本。
# React 的生命周期有哪些?
React 生命周期图谱如下:
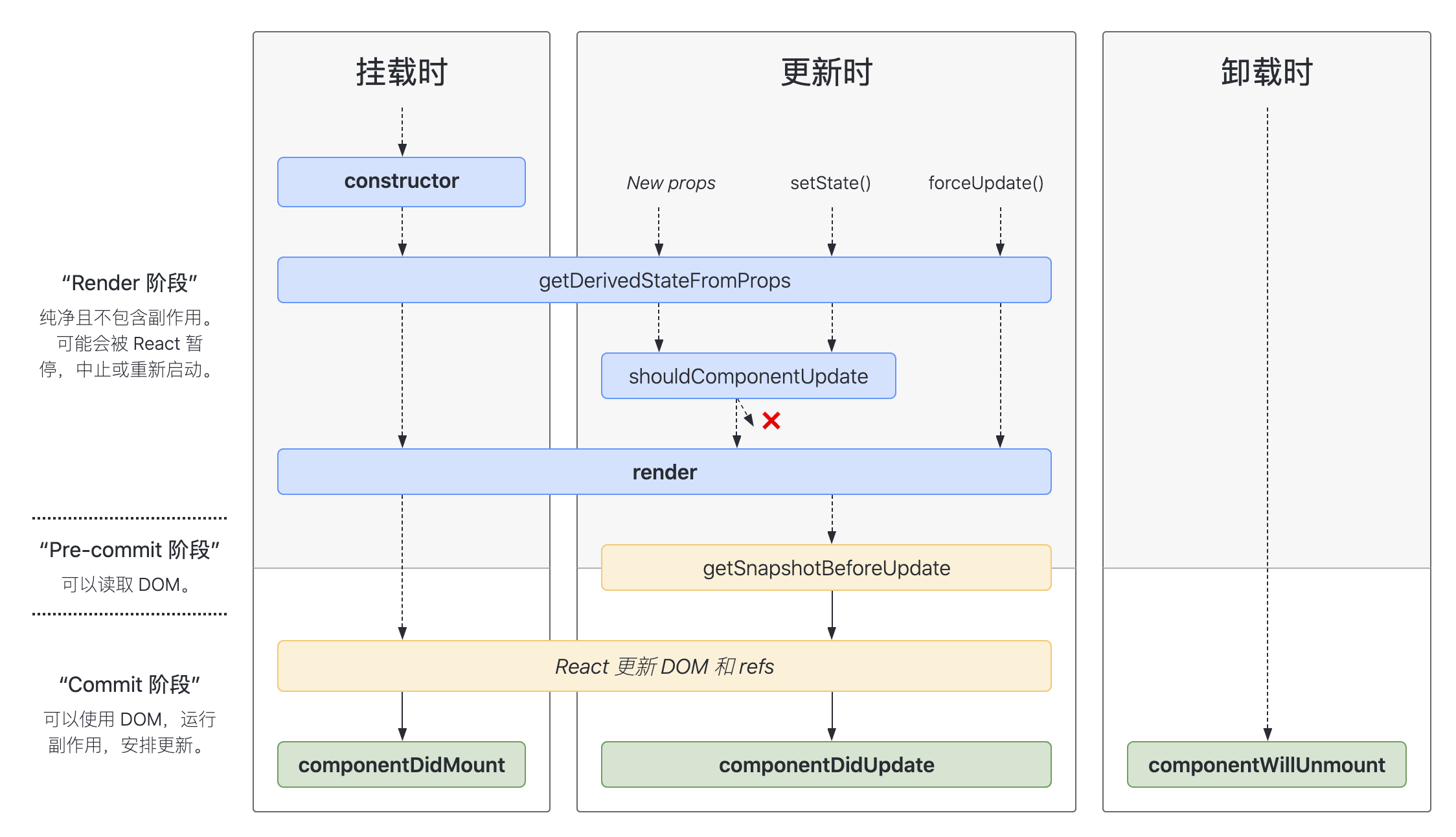 根据不同状态可以细分如下:
根据不同状态可以细分如下:
# 挂载
- constructor()
在 React 组件挂载之前,会调用它的构造函数 - static getDerivedStateFromProps()
getDerivedStateFromProps 会在调用 render 方法之前调用,并且在初始挂载及后续更新时都会被调用,它应返回一个对象来更新 state(注意这里是静态方法,代表你不能访问 this,使得 getDerivedStateFromProps 这个函数强迫变成一个纯函数,逻辑也相对简单,就没那么多错误了)。 - render()
渲染函数 render() 被调用 - componentDidMount()
componentDidMount() 会在组件挂载后(插入 DOM 树中)立即调用。依赖于 DOM 节点的初始化应该放在这里。如需通过网络请求获取数据,此处是实例化请求的好地方。
# 更新
- static getDerivedStateFromProps()
- shouldComponentUpdate()
根据 shouldComponentUpdate() 的返回值,判断 React 组件是否受当前 state 或 props 更改的影响。默认父组件的 state 或 prop 更新时,无论子组件的 state、prop 是否更新,都会触发子组件的更新,这会形成很多没必要的 render,浪费很多性能,使用 shouldComponentUpdate 可以优化掉不必要的更新。 - render()
- getSnapshotBeforeUpdate()
getSnapshotBeforeUpdate() 在最近一次渲染输出(提交到 DOM 节点)之前调用。它使得组件能在发生更改之前从 DOM 中捕获一些信息(例如,滚动位置)。此生命周期的任何返回值将作为参数传递给 componentDidUpdate()。 - componentDidUpdate()
componentDidUpdate() 会在更新后会被立即调用。
# 卸载
- componentWillUnmount()
componentWillUnmount() 会在组件卸载及销毁之前直接调用。在此方法中执行必要的清理操作,例如,清除 timer 等。
# 错误处理
- static getDerivedStateFromError()
此生命周期会在后代组件抛出错误后被调用。 它将抛出的错误作为参数,并返回一个值以更新 state - componentDidCatch()
此生命周期在后代组件抛出错误后被调用。
# PureComponent 和 Component 区别
当使用 component 时,父组件的 state 或 prop 更新时,无论子组件的 state、prop 是否更新,都会触发子组件的更新,这会形成很多没必要的 render,浪费很多性能。pureComponent 的优点在于:pureComponent 在 shouldComponentUpdate 只进行浅层的比较,只要外层对象没变化,就不会触发render,减少了不必要的render。
# 如何使用 Context 上下文
- 创建一个 context 对象
// 初始值为 { theme: themes.dark, toggleTheme: () => {} }
const ThemeContext = React.createContext({
theme: themes.dark,
toggleTheme: () => {},
});
- 使用 context.Provider 提供数据
render() {
return (
<ThemeContext.Provider value={this.state}>
<Content />
</ThemeContext.Provider>
);
}
- 使用 context.Consumer 或者挂载 contextType 或者 useContext 消费数据
// context.Consumer
render() {
return (
<ThemeContext.Consumer>
{({ theme, toggleTheme }) => (
<button
onClick={toggleTheme}
style={{backgroundColor: theme.background}}>
Toggle Theme
</button>
)}
</ThemeContext.Consumer>
);
}
// 挂载 contextType
class MyClass extends React.Component {
...
render() {
let value = this.context;
}
}
MyClass.contextType = ThemeContext;
// useContext
const value = useContext(ThemeContext);
需要注意的是 Provider 必须是 Consumer 的祖先元素。
# React 父组件调用子组件的方法
- 使用 forwardRef 和 useImperativeHandle 在子组件中暴露方法
function FancyInput(props, ref) {
const inputRef = useRef();
useImperativeHandle(ref, () => ({
focus: () => {
inputRef.current.focus();
}
}));
return <input ref={inputRef} ... />;
}
FancyInput = forwardRef(FancyInput);
- 父组件使用 ref 调用子组件方法
function parentContainer() {
const childRef = useRef();
useEffect(() => {
childRef.current.focus();
}, []);
return <FancyInput ref={childRef} />
}
# React 组件更新流程
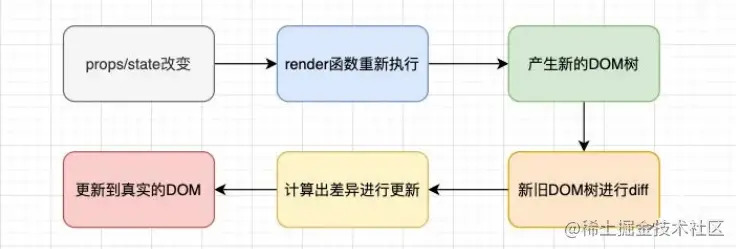
# React 虚拟 DOM diff 算法
React 的虚拟 DOM(Virtual DOM)是其核心特性之一,它允许开发者编写声明式的 UI 代码并且不用担心具体的性能细节。React 使用虚拟 DOM 来优化 UI 的更新过程,使得只有当数据发生变化时,才会重新渲染组件。React 的 diff 算法是优化这个过程的关键。
React 的 diff 算法是一种启发式算法,它通过两个假设来优化应用程序的性能:
两个不同类型的元素会产生不同的树。 当 React 在对比两棵树时,如果发现元素的类型不同,它会直接删除旧树,并且建立一棵新树。
通过
key属性,可以在不同的渲染中识别出哪些元素是相同的。 在数组中渲染多个子组件时,应该给每个子组件赋予一个独一无二的key属性。这样,React 可以通过key来匹配原始树形结构中的子元素和后来的子元素。
React 的 diff 算法主要分为三个步骤:
# 对比不同类型的元素
当根元素是不同类型的组件时,React 会拆卸旧树并建立新树。例如,当一个 <div> 变成了 <span>,或者当一个 MyComponent 变成了 YourComponent,React 会销毁旧的树并完整地重新建立起新的树。
# 对比同一类型的元素
当比较两个相同类型的 React 元素时,React 会保留 DOM 节点,并且仅更新改变了的属性。例如,如果一个元素的 className 从 before-class 变成了 after-class,React 将只修改 className 属性。
# 对比同类型的组件
当一个组件更新时,如果它的类型相同,React 会保留组件实例不变,只会更新组件的 props。然后,调用该组件的 render 方法,接着 diff 算法会对比前后两次渲染结果的差异,并且更新 DOM。
# 对子节点的 Diff
对于子节点,React 也会进行 diff 操作:
没有
key的子节点: React 会逐个对比旧树和新树的子节点,如果子节点在两棵树中的位置发生了变化,那么 React 可能会产生不必要的 DOM 更新。有
key的子节点: 当子节点拥有key时,React 会使用key来匹配旧树和新树中的子节点。这样,即使子节点的位置发生变化,React 也能够正确地识别出它们,从而避免不必要的 DOM 操作。
React 的 diff 算法是非常高效的,因为它减少了对 DOM 的操作次数,而 DOM 操作通常是 Web 应用中性能瓶颈的主要原因。然而,diff 算法并不是完美的,如果开发者不合理地使用 key 或者在组件结构中做出大的变动,仍然可能会导致性能问题。因此,合理地利用 React 的 diff 算法,可以帮助开发者构建高性能的 Web 应用。